
I. Introduction: Building on a Necessary Critique
Dr. Claudio Fantinuoli’s recent article, "Is AI Interpreting Ready for Prime Time?" (July 19, 2025), provides a timely examination of AI interpreting’s limitations and an invaluable grounding for our field. While fully endorsing his caution against premature high-stakes adoption, this response seeks to augment his framework with empirical evidence from WHO validation studies and documented market dynamics that warrant equal scholarly attention. Our shared goal remains elevating industry standards through academically rigorous discourse. However, this analysis understates two critical dimensions:
This response extends Fantinuoli’s framework by integrating decision theory, forensic analysis of the ITU’s "AI for Good Global Summit" documented anomalies, and the WHO’s reported data. My aim is not to contradict but to fortify his conclusions with evidence demanding scholarly urgency.
II. The WHO Study: Methodological Rigor, Not Curiosity
Dr. Fantinuoli characterizes the WHO’s pilot as potentially demonstrating "that AI isn’t ready." This underrepresents its scientific contribution:
Results Dr. Fantinuoli’s article omits:
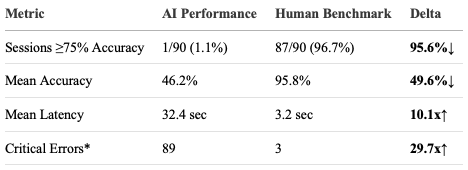
This isn’t a proof-of-concept but a validation crisis. When error probability exceeds 50% in contexts where mistakes threaten human welfare (e.g., misinterpreting vaccine side effects), "unreadiness" becomes a risk management failure. These results represent not technical immaturity but operational infeasibility for high-stakes contexts where error margins approach zero.
III. Beyond "Wishful Thinking": The Fraud-Permissioned Market
Dr. Fantinuoli attributes client overconfidence to cognitive bias ("wishful thinking") and aggressive marketing. While valid, this underestimates deliberate deception.
Case Analysis: 2025 AI for Good Global Summit (Geneva)
At this UN-coordinated event, a prominent RSI platform (hereafter "Platform I") engaged in concerning practices:

This transcends hype—it is fraudulent misrepresentation. By erasing human labor, vendors manufacture "evidence" of AI’s prime-time readiness. Dr. Fantinuoli’s recommendation to "evaluate case by case" becomes void when vendors control case integrity.
IV. Decision Theory: Quantifying the Deception Tax
Dr. Fantinuoli’s call for "sobriety" needs mathematical grounding. Rational procurement follows Expected Utility (EU) Theory:

For AI interpreting:
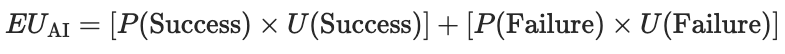
Real-World Calculation:
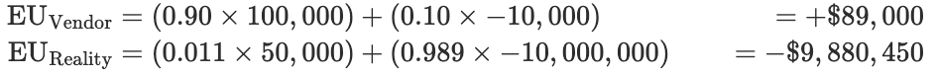
The deception tax: $9.97M in hidden risk. This isn’t bias—it’s market failure.
V. Toward Evidence-Based Procurement: Nuancing the Discourse
Dr. Fantinuoli’s proposed solutions (e.g., "case-by-case evaluation") are necessary but insufficient against systemic fraud. We must:
1. Mandate Forensic Transparency
2. Decentralize Validation
3. Contractual Enforcement
VI. Conclusion: From Readiness to Accountability
Dr. Fantinuoli’s core thesis—that AI interpreting remains unfit for prime time—is empirically sound. However, the 2025 AI for Good Global Summit incident demonstrates that without:
1. Scholarly consensus on validation standards,
2. Industry-wide transparency requirements,
3. Decision-theoretic procurement frameworks,
Market distortions will persist. Let us advance Dr. Fantinuoli’s vital critique by demanding accountability—not just readiness.
Accredited English-Mandarin (Chinese) Consultant Conference Interpreter based in Singapore, Member of AIIC and ATA
Remote Simultaneous Interpreting (RSI) Expert
If you want me to provide you Interpretation/Translation service in English to Chinese (Mandarin) and vice versa, or a quotation for conference interpreting services of any languages, simply contact me by phone or email.
Dr. Bernard Song
Mob: (+65) 9478 0176
Tel: (+65) 6610 6718
Email: psong@BernardSong.com
© 2022. Bernard Song. All Rights Reserved.


